
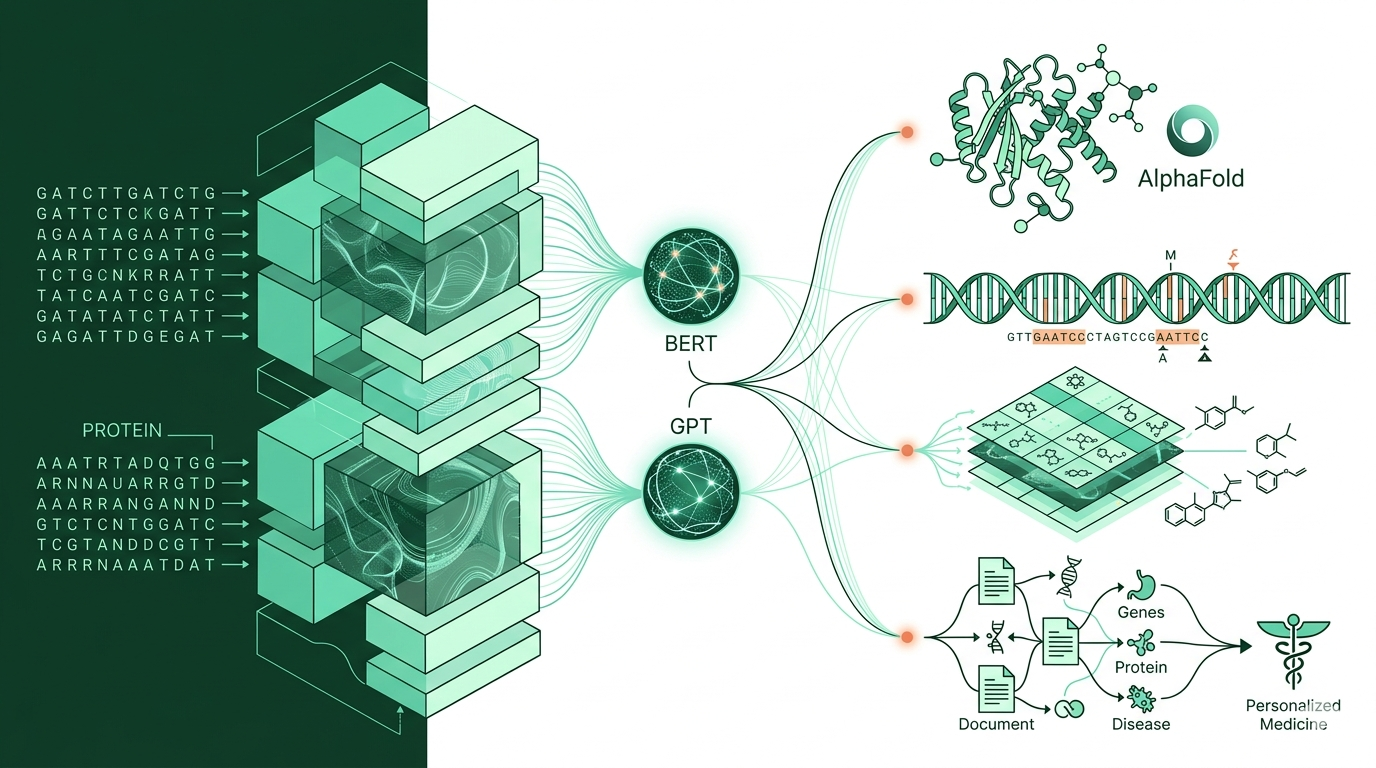
Velké jazykové modely (LLMs), jako jsou BERT či GPT, představují revoluci nejen v oblasti zpracování přirozeného jazyka, ale nově i v bioinformatice tedy ve vědecké disciplíně, která analyzuje obrovské objemy biologických dat pomocí výpočetních metod. Tyto pokročilé modely staví na architektuře transformerů, pracují s miliardami parametrů a umožňují odhalovat nové vzorce a souvislosti v genetických, proteinových i klinických datech.
Základní síla LLMs spočívá ve schopnosti udržet kontext a chápat sekvence — tedy nejen slova či věty, ale i složité biologické řetězce, jako jsou DNA nebo aminokyselinové sekvence proteinů. Díky tomu dokáže AI pomáhat při rychlé analýze genomu, predikci struktur proteinů, objevování nových léků nebo přesnějším určování biologických markerů u nemocí.
Článek představuje přehled dnes dostupných specializovaných modelů, které jsou již využívány ve výzkumu: DNABERT, ProteinBERT, RNABERT, SMILES-BERT, MolGPT nebo GeneBERT. Tyto modely mají unikátní schopnost učit se „jazyk“ DNA, proteinů a dalších biomolekul a tím objevovat nové struktury, funkce i vztahy v biologii.
K hlavním oblastem využití LLMs v bioinformatice patří:
- Predikce struktury proteinů (např. AlphaFold nebo ProtGPT2), které urychlují vývoj nových léků a pochopení funkcí proteinů v organismu.
- Sekvenování a analýza DNA a RNA pomocí speciálních algoritmů, jež dokážou rozpoznávat významné motivy či mutace napříč různými druhy.
- Objevování a design nových molekul pro cílenou léčbu (například MolGPT, ChemBERTa).
- Analýza genové exprese a její regulace, což má význam například u onkologických onemocnění nebo pro vývoj a diferenciaci buněk a tkání.
- Automatizovaná extrakce informací z vědeckých textů: modely jako BioBERT dokážou vyhledávat důležité vztahy mezi geny, proteiny a nemocemi přímo z tisíců publikací.
- Zpracování dat pro individuální medicínu: Modely pomáhají spojovat genetické profily pacientů s návrhem na míru šité léčby.
Velký důraz je kladen také na nové výzvy a úskalí: potřeba lepší interpretovatelnosti (aby lékaři rozuměli, jak model k odpovědím došel), etika, korekce zkreslení dat a riziko tzv. „halucinací“ AI, kdy může model generovat nereálné výsledky.
Současný vývoj ukazuje, že velké jazykové modely se rychle stávají nepostradatelným pomocníkem v laboratořích i zdravotnictví. Urychlují výzkum, rozšiřují možnosti analýzy dat a posouvají medicínu směrem k personalizovanému přístupu — tedy k léčbě šité na míru každému člověku.
Pro firmy a jednotlivce v oblasti genetického testování, biotechnologií či personalizované medicíny znamená tato revoluce nejen nové příležitosti, ale i potřebu vzdělání a správného použití moderních nástrojů pro využití AI ve prospěch vědy i pacientů.
Zdroj:





